
Datenmodellierung
In diesem Blog soll es um die Dokumenten-orientierte Datenmodellierung in der MongoDB und den lesenden und schreibenden Zugriff auf diese Daten gehen.
Unser ursprüngliches, normalisiertes relationales Datenmodell sah wie folgt aus:
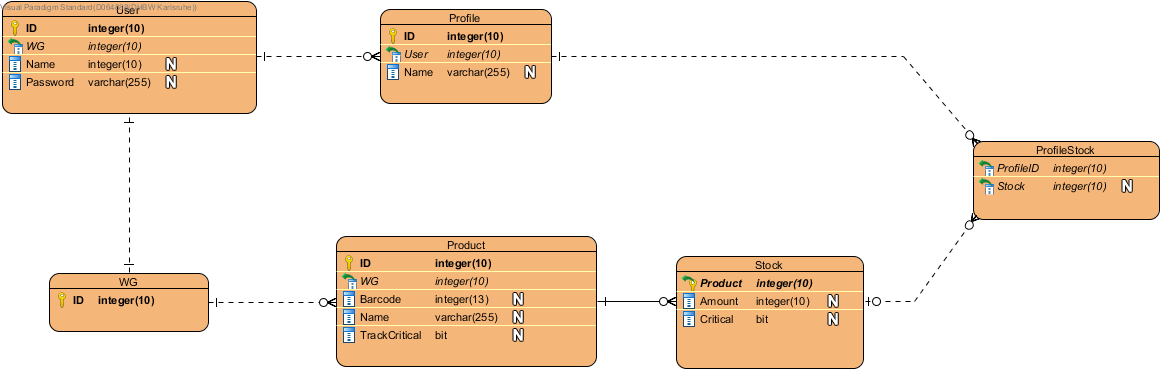
Fachlich wurde diese Modellierung jedoch noch geändert. Die n:m Beziehung zwischen einem Profil und dem Bestand (realisiert mit der Relation ProfileStock) ist nicht notwendig. Stattdessen ist der Bestand entweder einem Profil zugeordnet (Attribut owner) oder wird von allen Profilen geteilt (Attribut shared). Des Weiteren hat die Entität Profil ein optionales Attribut image, welches für das Profilbild verwendet wird.
Wie bereits in vorherigen Blog-Beiträgen erläutert, haben wir uns dazu entschieden, eine MongoDB zu benutzen. Dies ist die meist verbreitete NoSQL Datenbank. Im Gegensatz zu einer SQL Datenbank ist kein fixes Datenschema erforderlich. Die Daten werden in folgenden Strukturen gespeichert:
- Collection: Sammlung von Dokumenten, ähnlich einer SQL-Tabelle
- Dokument: Objektinstanz mit verschiedenen Attributen, ähnlich einer Tabellenzeile in SQL. Ein MongoDB Dokument kann jedoch beliebig tief sein (Subdokumente) und auch Arrays als Attribute besitzen. Jedes Dokument kann anders aussehen, da kein Schema definiert ist.
Für die MongoDB ist daher kein normalisiertes Datenmodell notwendig. Im Gegenteil, Subdokumente und Arrays sind sogar erwünscht. Daten, die zusammengehören, sollen ohne Joins schnell und einfach gelesen werden. Die Modellierung wird dadurch komplexer, da viele unterschiedliche Möglichkeiten bestehen, wie die Daten abgebildet werden. Wichtigster Anhaltspunkt ist bereits in dieser frühen Phase der Entwicklung die Modellierung der notwendigen Datenabfragen. Ziel ist es, das relationale Modell so zu denormalisieren, dass die Performance von Datenabfragen optimiert wird. Folgende Punkte sollten dabei berücksichtigt werden:
- Die Dokumententiefe (eingebettete Subdokumente) sollte nicht zu tief sein, da beim Lesen eines Dokumentes immer das gesamte Dokument gelesen wird
- Zusammengehörende Daten schon beim Schreiben der Daten joinen
- Datenduplikate sind in gewissem Rahmen erlaubt
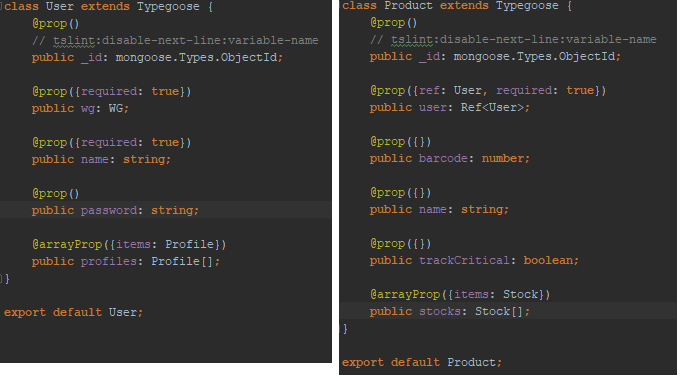
Die folgende Abbildung zeigt unsere dokumentenorientierte Modellierung. Wie zu sehen ist, sind nur zwei Collections notwendig. Die Dokumente der Collection „User“ beinhalten auch alle Profile des Users, genauso wie die Produkt-Dokumente alle Bestände beinhalten.
Datenzugriff
In einer der letzten Semester haben wir bereits die Java Persistence API kennengelernt. Dies ist ein Objekt-Relationaler-Mapper (ORM), der den Zugriff auf die Datenbank stark vereinfacht. Die DB-Tabellen werden dabei auf Java Klassen und Objekte gemappt. Mithilfe von Annotationen kann das Mapping konfiguriert werden. Für die MongoDB existiert mit der Mongoose Library ein ähnliches Framework. Dies wird als Object-Document-Mapper bezeichnet (ODM). Mithilfe eines definierten Models wird der Zugriff auf die Datenbank vereinfacht. Models entsprechen Klassen, deren Instanzen beispielsweise die Methode save besitzen, um ein zugehöriges Dokument in der DB zu erstellen. So können die Vorteile einer NoSQL Datenbank mit den Vorteilen eines Datenschemas kombiniert werden.
Bei der Verwendung von Typescript zusammen mit Mongoose sind wir dabei jedoch auf ein Problem gestoßen. Unsere Datenobjekte mussten doppelt definiert werden, einmal in Form einer Typescript Klasse zum Nutzen der Typisierungsmöglichkeiten und noch einmal zum Definieren der Mongoose-Model.
Nach kurzer Recherche sind wir auf Typegoose gestoßen. Dies ist ein npm-Paket, welches zum Ziel hat, das oben genannte Problem zu lösen. Dabei wird nur die TS Klasse definiert und, ähnlich wie bei der JPA, um Annotationen erweitert. Wichtig sind hier die Annotationen @prop (normales Attribut) und @arrayProp (Array-Attribut). Auch Referenzen auf andere Dokumente (über die Dokument-ID) sind möglich. Mithilfe von Vererbung wird für jede Klasse eine Methode getModelForClass bereitgestellt, welche für die Klasse das dazugehörige Mongoose-Model zurückgibt. Ein Beispiel für eine solche Klasse mit Annotationen ist bereits in der obigen Abbildung zu sehen gewesen.
Zusammenfassend ist aus unserer Sicht eine MongoDB gut geeignet, wenn Entitäten oft gemeinsam gelesen werden, dies im Voraus bereits ersichtlich ist und keine großen Änderungen im Funktionsumfang der Anwendung mehr erwartet werden.
Weitere Infos: https://www.tutorialspoint.com/mongodb/mongodb_data_modeling.htm
Sehr interessant, vor allem die Umsetzung mit node.js. Vielen Dank.