
Komponenten des Backend von Smart Drive
Unser Backend ist fertig und lauffähig. Im Folgenden werden die einzelnen Komponenten unseres Backend dokumentiert und der Weg der Sensordaten von der Erfassung bis zur grafischen Darstellung im Frontend dargestellt.
Überblick
Die folgende Darstellung zeigt den Aufbau unseres Backend.
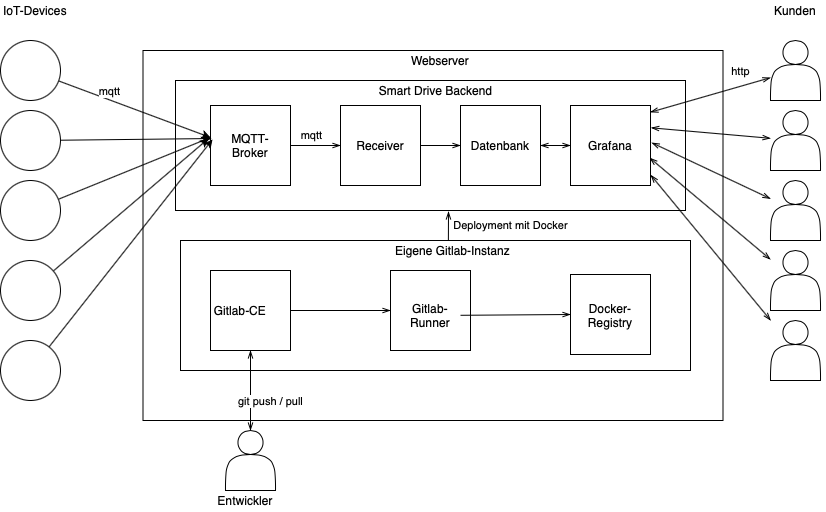
Jedes Quadrat in der Abbildung stellt einen Docker-Container dar. Die Rechtecke gliedern diese Container in logische Einheiten. Diese sind hier zum einen das Smart Drive Backend und zum anderen unsere eigene Instanz von Gitlab. Wie das äußere Rechteck zeigt, laufen alle Container auf einem einzigen Webserver und somit auf einem einzigen Docker-Host. Zum Zugriff auf den Webserver sind drei Möglichkeiten dargestellt. Die Kreise links außerhalb des Servers stellen die IoT-Devices unserer Kunden dar und die rechts abgebildeten Personen die dazu gehörenden Kunden. Die Person unterhalb des Servers steht für das Entwicklungsteam von Smart Drive, das mit der Gitlab-Instanz über git-Befehle interagiert. Das Deployment der Komponenten unseres Backends erfolgt dann automatisiert durch unsere eigene Gitlab-Instanz.
Die Pfeile im oberen Teil der Abbildung bilden von links nach rechts den Weg der Sensorwerte von der Erfassung durch Sensoren bis zum Kunden ab. Wenn neue Software im System eingespielt wird, beginnt der Weg beim Entwicklerteam und läuft über die Gitlab-Instanz bis zum Deployment im Smart Drive Backend.
Dokumentation der einzelnen Komponenten
MQTT-Broker
Als MQTT-Broker kommt Eclipse Mosquitto zum Einsatz. Die Software wird als fertiges Docker Image auf Docker Hub bereitgestellt, sodass die Anwendung sofort einsatzfähig ist und lediglich konfiguriert werden muss. Ziel der Konfiguration ist es, einen Verbindungsaufbau nur mit Benutzername und Passwort zu erlauben. Außerdem soll der Standard Port 1883 verwendet werden.
Die Konfigurationsdatei zu den oben genannten Anforderungen besteht aus den folgenden Zeilen.
listener 1883 allow_anonymous false password_file /mosquitto/config/pw
- listener 1883 sorgt dafür, dass der MQTT-Broker auf Port 1883 lauscht. Die nachfolgenden Zeilen beziehen sich dann auf den Listener an diesem Port. Es wäre möglich auf anderen Ports weitere Listener mit anderen Einstellungen zu erstellen.
- allow_anonymous false verbietet anonyme Verbindungen. Zur Herstellung ist also im Gegensatz zur früheren Konfiguration ein Benutzername und ein Passwort notwendig. Diese Einstellung sichert lediglich den Zugang zum Broker ab, jedoch nicht die übertragenen Daten. Diese sind weiterhin unverschlüsselt. Ebenso die Zugangsdaten, welche somit ohne großen Aufwand abgehört werden können. Daher ist die zusätzliche Konfiguration der Verschlüsselung zum produktiven Betrieb unbedingt erforderlich.
- password_file /mosquitto/config/pw gibt den Pfad zu der Datei an, die eine Liste aller Kombinationen aus Benutzernamen und Passwort enthält. Der Pfad bezieht sich auf das Dateisystem des Docker Containers. Hier wurde der Pfad gewählt an dem auch die Konfigurationsdatei selbst zu finden ist. Die Erstellung der Datei wird weiter unten beschrieben.
Der Inhalt der Passwortdatei muss mit einem mitgelieferten Tool generiert werden, damit die Passwörter nicht im Klartext enthalten sind. Dazu werden alle gewünschten Kombinationen aus Benutzername und Passwort zunächst im Klartext in die Datei geschrieben. Dabei werden die einzelnen Kombinationen durch einen Zeilenumbruch getrennt sowie Benutzername und Passwort durch einen Doppelpunkt. Die weitere Verarbeitung der Datei erfolgt zu einem späteren Zeitpunkt, da der Container dafür bereits laufen muss.
Beim Start des Containers ist zu beachten, dass der Port 1883 nach außen freigegeben wird und die beiden erstellten Dateien als Volume in das Dateisystem des Containers eingebunden werden. Beide Dateien müssen im Container unter dem Pfad /mosquitto/config/ zu finden sein. Aus den genannten Anforderungen ergibt sich der folgende Inhalt für docker-compose.yml. Dabei wird angenommen, dass die beiden oben erstellten Dateien im Home-Verzeichnis unter mqtt/ zu finden sind.
version: "3"
services:
mqtt:
image: eclipse-mosquitto:latest
container_name: iot-mqtt
restart: unless-stopped
ports:
- 1883:1883
volumes:
- $HOME/mqtt/mosquitto.conf:/mosquitto/config/mosquitto.conf
- $HOME/mqtt/pw:/mosquitto/config/pw
Ist die Datei docker-compose.yml mit diesem Inhalt erstellt, wird der Container mit
docker-compose up -d
gestartet. Bevor eine Verbindung per MQTT-Client beispielsweise aus Python heraus aufgebaut werden kann, muss die Passwort-Datei noch ins richtige Format gebracht werden. Dazu wird das Tool mosquitto_passwd im Docker Image mitgeliefert. Um die Datei entsprechend umzuwandeln, wird innerhalb des gerade gestarteten Containers ein entsprechender Befehl abgesetzt. Dafür wird zunächst eine innerhalb des Containers laufende shell aufgerufen. Bash ist nicht installiert, deshalb muss auf sh zurückgegriffen werden. Dazu wird der folgende Befehl auf dem Docker Host aufgerufen.
docker container exec iot-mqtt sh
Anschließend wechselt man mit
cd /mosquitto/config
in das Verzeichnis mit den beiden Dateien. Dort kann dann mit
mosquitto_passwd -U pw
die Umwandlung durchgeführt werden. Mit exit wird die Shell des Containers verlassen und auf den Docker Host zurückgekehrt. Betrachtet man nun den Inhalt der Passwort-Datei, ist zu sehen, dass die Passwörter nicht mehr im Klartext zu sehen sind. Sollte immer noch kein Verbindungsaufbau möglich sein, kann der Container gelöscht und eine neue Instanz gestartet werden. Die Datei bleibt dabei unberührt, da sie in einem Docker Volume liegt.
Nun sollte mit der Angabe der öffentlichen IP des Webservers, dem Port 1883 sowie einer in der Passwort-Datei angegebenen Kombination aus Benutzername und Passwort ein Verbindungsaufbau zum Broker möglich sein. Somit ist die erste Komponente des Smart Drive Backend einsatzbereit.
MQTT-Receiver
Damit die per MQTT versandten Messwerte in der Datenbank gespeichert werden, ist ein Stück Software notwendig, dass diese Aufgabe übernimmt. Dazu wird das entsprechende Topic am zuvor aufgesetzten MQTT-Broker abonniert, die Messwerte aus der empfangenen Nachricht gelesen und in entsprechende Datentypen umgewandelt und anschließend pro Messwert eine Zeile in eine Datenbanktabelle geschrieben.
Das Programm wurde in Python implementiert und basiert auf dem bereits gezeigten Skript zum Empfang von MQTT Nachrichten. Daher wird dieser Teil nicht weiter erläutert. Neu hinzu kommt die Datenbankanbindung. Als Datenbank kommt PostgreSQL zum Einsatz. Zur Verbindung mit PostgreSQL steht für Python die Bibliothek psycopg2 zur Verfügung, die mit
pip install psycopg2-binary
installiert wird. Anschließend wird das Modul wie folgt importiert und die Verbindung zur Datenbank aufgebaut. Dazu müssen zuvor die Verbindungsparameter in den entsprechenden Attributen der Klasse gespeichert werden.
import psycopg2 as pg
self._db_connection = pg.connect(
host = self._db_host, # dazu später mehr
port = self._db_port, # Standard: 5432
user = self._db_user, # Datenbank User
password = self._db_password # Passwort für DB-User
dbname = self._db_dbname # Name der Datenbank
)
self._db_cursor = self._db_connection.cursor()
Das Cursor Objekt wird später zum Ausführen von SQL-Statements verwendet.
Die empfangenen Nachrichten liegen als JSON String vor. Dabei ist zu beachten, dass immer eine Liste von Messwerten übertragen wird, auch wenn nur ein einziger Messwert in einer Nachricht enthalten ist. In der Liste befindet sich also immer mindestens ein Objekt, das in den Attributen die Messwerte enthält. Um den String zu parsen, kann der empfangene Payload einfach an die Methode loads() des Moduls json übergeben werden. Als Ergebnis erhält man eine Liste von Dictionaries, die in den Attributen X_acceleration, Y_acceleration, Z_acceleration, X_rotation, Y_rotation sowie Z_rotation die Messwerte des Sensors enthält. Außerdem wichtig sind die Attribute _id und _device_uuid, damit die Messwerte zeitlich korrekt sortiert werden und einem bestimmten Device und damit einem Kunden zugeordnet werden können. Zu beachten ist, dass alle Werte als String vorhanden sind, vor dem Schreiben in die Datenbank also in Float bzw. Integer umgewandelt werden müssen. Der folgende Codeblock zeigt das Umwandeln des Payload in Objekte sowie den Aufruf einer weiteren Methode, der als Argumente die bereits umgewandelten numerischen Werte übergeben werden.
message_list = json.loads(message.payload)
for m in message_list:
self._write_message_to_db(
float(m['_id'][:13]) / 1000, # Division für Mikrosekunden
m['_device_uuid'],
float(m['X_acceleration']),
float(m['Y_acceleration']),
float(m['Z_acceleration']),
int(m['X_rotation']),
int(m['Y_rotation']),
int(m['Z_rotation'])
)
Als letzter Schritt werden nun die Werte in die Datenbanktabelle drive_data geschrieben. Dazu wird ein einfaches INSERT-Statement verwendet. Die Bibliothek psycopg2 ermöglicht das Einsetzen von Werten über Platzhalter, die im einfachsten Fall als Tupel in entsprechender Reihenfolge übergeben werden. Diese Möglichkeit ist selbst zusammengesetzten Strings in jedem Fall vorzuziehen, da hier automatisch bestimmte Zeichen maskiert werden und so vor SQL-Injections geschützt wird.
self._db_cursor.execute(
"""INSERT INTO drive_data VALUES (
to_timestamp(%s),
%s,
%s,
%s,
%s,
%s,
%s,
%s
);""", (
timestamp,
device_id,
X_acc,
Y_acc,
Z_acc,
X_rot,
Y_rot,
Z_rot
)
)
self._db_connection.commit()
Da die Reihenfolge der Werte nicht explizit angegeben wird, muss die Reihenfolge der Spalten in der Datenbank eingehalten werden. Der Zeitstempel wird von den Devices als UNIX-Timestamp, also die Anzahl der Sekunden seit Anfang 1970, versandt. Im vorherigen Schritt wurde diese Ganzzahl bereits durch 1.000 dividiert, da die Zeit bis auf 1/1.000 Sekunde genau angegeben ist. Die Funktion to_timestamp() der PostgreSQL-Datenbank wandelt einen solchen Wert in einen Timestamp um, der in einer Spalte vom Typ TIMESTAMP gespeichert wird. Liest man den Wert mit der hier verwendeten Python Bibliothek wieder aus, erhält man automatisch ein Objekt vom Typ datetime.
Das fertige Programm wird in ein eigenes Docker Image verpackt und über Gitlab CI/CD automatisch auf dem Webserver deployed. Durch dieses Vorgehen können Änderungen ohne Aufwand live gesetzt werden, wobei nur ein sehr kurzer Ausfall in Kauf zu nehmen ist, da alle Schritte automatisiert ablaufen und somit direkt hintereinander ausgeführt werden.
Datenbank
Als DBMS setzen wir in unserem Backend eine PostgreSQL-Datenbank ein. Die Entscheidung ist auf dieses Datenbanksystem gefallen, da hier vor allem im Vergleich zu MariaDB vielfältigere Möglichkeiten des Einsatzes von Machine Learning Technologien bereit stehen. So ist in PostgreSQL Python-Unterstützung integriert und die wichtigsten Bibliotheken wie Numpy, Pandas PyTorch und Tensorflow in der Datenbank lauffähig. Diese Technologien werden für unser datengetriebenes Geschäftsmodell später essentiell sein und daher bei der Auswahl berücksichtigt. Weiterhin kann unser eingesetztes Frontend-Tool out-of-the-box eine PostgreSQL-Datenbank als Data Source verwenden. Damit ist die Integration auch hier gesichert.
Die Anwendung steht auf Docker Hub als fertiges Docker Image zur Verfügung und kann somit ohne großen Aufwand in Betrieb genommen werden. Über Umgebungsvariablen müssen lediglich das Passwort sowie der Name der Datenbank gesetzt werden. Damit die in der Datenbank gespeicherten Daten über die Lebensdauer einer Container-Instanz hinaus persistent sind, wird das Verzeichnis /var/lib/postgresql/data in einem Volume gespeichert. Der Eintrag in der docker-compose.yml sieht wie folgt aus.
iot-db:
image: postgres:11-alpine
container_name: iot-db
restart: unless-stopped
environment:
- POSTGRES_PASSWORD=pw
- POSTGRES_DB=iot
volumes:
- $HOME/iot/db:/var/lib/postgresql/data
Es wird kein Port freigegeben, da die Datenbank außerhalb des Webservers aus Sicherheitsgründen nicht erreichbar sein soll. Das Image stellt jedoch automatisch den Port 5432 für eingehende Verbindungen zur Verfügung. Da in unserem Szenario der MQTT-Receiver und das Frontend-Tool eine Verbindung herstellen und diese ebenfalls als Docker Container im selben Docker Netzwerk betrieben werden, ist die Datenbank für diese Komponenten erreichbar.
Grafana
Als Frontend-Tool, das unseren Kunden die Einsicht in ihre Fahrdaten ermöglicht, kommt Grafana zum Einsatz. Auch diese Anwendung steht als Docker Image zur Verfügung. Die Verwendung des bereitgestellten Image ist in der Dokumentation von Grafana erläutert.
Da die Weboberfläche aus dem Internet erreichbar sein soll, wird der entsprechende Port freigegeben. Grafana nutzt standardmäßig den Port 3000. Dieser wird zunächst beibehalten, sollte jedoch für den produktiven Einsatz auf den Standard-Port für SSL-Verbindungen 443 umgestellt werden. Wie bei den anderen Komponenten des Backend, wird ein Docker Volume verwendet, um die im Container anfallenden Daten zu speichern und diese über die Lebensdauer des Containers hinaus zu sichern. Über Umgebungsvariablen sind einige Einstellungen zu setzen, darunter auch die öffentliche Domain der Weboberfläche. Insgesamt ergibt sich der folgende Eintrag für docker-compose.yml.
iot-grafana:
image: grafana/grafana
container_name: iot-grafana
restart: unless-stopped
ports:
- 3000:3000
user: "1001"
volumes:
- $HOME/iot/grafana:/var/lib/grafana
environment:
- GF_SERVER_PROTOCOL=http
- GF_SERVER_DOMAIN=smart-drive.johannes-wessiepe.de
- GF_SERVER_ROOT_URL=http://smart-drive.johannes-wessiepe.de:3000
- GF_SECURITY_ADMIN_USER=user
- GF_SECURITY_ADMIN_PASSWORD=pw
labels:
- traefik.enable=true
- traefik.http.routers.iot-grafana.rule=Host(`smart-drive.johannes-wessiepe.de`)
- traefik.http.services.iot-grafana.loadbalancer.server.port=3000
Neu für diese Anwendung ist die Angabe einer User-ID mit user: „1001“. Diese ID wird für den User innerhalb des Containers verwendet. In diesem Fall wurde die ID des Users angegeben, der die Docker Container startet und somit Eigentümer des Verzeichnis‘ des Docker Volume ist. Dies hat dann den Vorteil, dass die im Volume gespeicherten Daten auch außerhalb ohne root-Rechte mit voller Berechtigung verfügbar sind. Die User-ID des aktuell angemeldeten User kann mit dem Befehl id ausgegeben werden.
Damit die Weboberfläche unter der Subdomain smart-drive erreichbar ist, muss in der Sektion labels die entsprechende Regel für den Reverse-Proxy angegeben werden. Dieser kümmert sich dann automatisch um das korrekte Routing sowie die Erstellung und Erneuerung des SSL-Zertifikats per Let’s Encrypt. Das Zertifikat wird aktuell jedoch noch nicht eingesetzt, da SSL nur über den Port 443 erlaubt ist.
Um die Daten aus der PostgreSQL-Datenbank im Frontend darstellen zu können, wird die Datenbank als Data Source eingebunden. Dazu öffnet man die Weboberfläche und meldet sich mit den im Dockerfile festgelegten Daten als Administrator an. Danach kann im linken Menü unter Configuration -> Data Sources eine neue Data Source vom Typ PostgreSQL angelegt werden. Als Verbindungsparameter trägt man die in den Umgebungsvariablen des Datenbank-Containers festgelegten Daten wie Passwort und Datenbankname ein. Als User steht standardmäßig postgres zur Verfügung. Erreichbar ist die Datenbank im Docker Netzwerk unter dem Namen des Service, wie in der docker-compose.yml angegeben. In diesem Fall ist der Host iot-db:5432. Die übrigen Einstellungen verbleiben auf den Standardwerten bzw. leer.
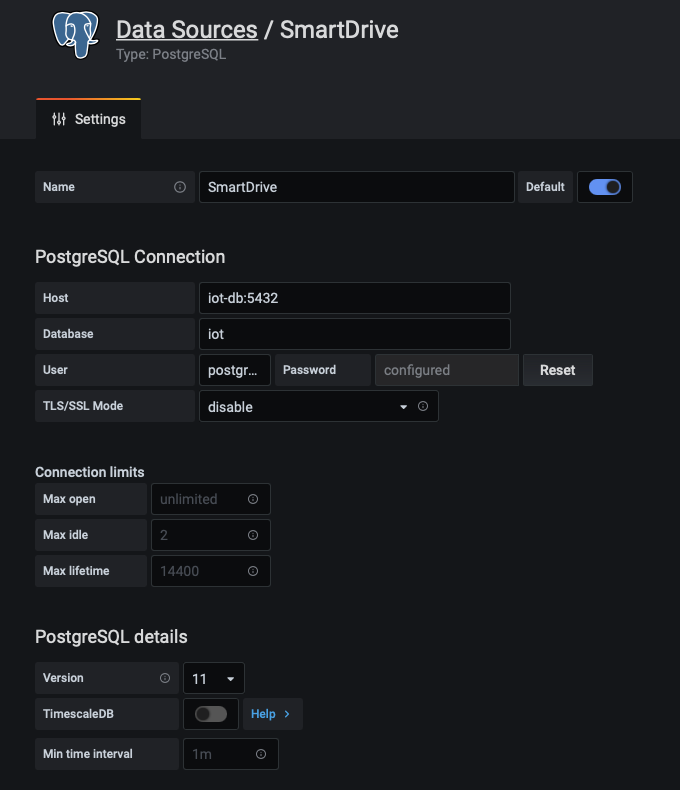
Legt man jetzt ein neues Dashboard an, kann die soeben eingerichtete Data Source ausgewählt werden und Daten aus der Tabelle selektiert werden. Das weitere Vorgehen wurde bereits in diesem Beitrag beschrieben.